Networking
Nomad is a workload orchestrator and so it focuses on the scheduling aspects of a deployment, touching areas such as networking as little as possible.
Networking in Nomad is usually done via configuration instead of infrastructure. This means that Nomad provides ways for you to access the information you need to connect your workloads instead of running additional components behind the scenes, such as DNS servers and load balancers.
This can be confusing at first since it is quite different from what you may be used to from other tools. This section explains how networking works in Nomad, some of the different patterns and configurations you are likely to find and use, and how Nomad differs from other tools in this aspect.
Allocation networking
The base unit of scheduling in Nomad is an allocation, which means that all
tasks in the same allocation run in the same client and share common resources,
such as disk and networking. Allocations can request access to network
resources, such as ports, using the network block. At its
simplest configuration, a network block can be defined as:
Nomad reserves a random port in the client between min_dynamic_port and
max_dynamic_port that has not been allocated yet and creates a port
mapping from the host network interface to the allocation.
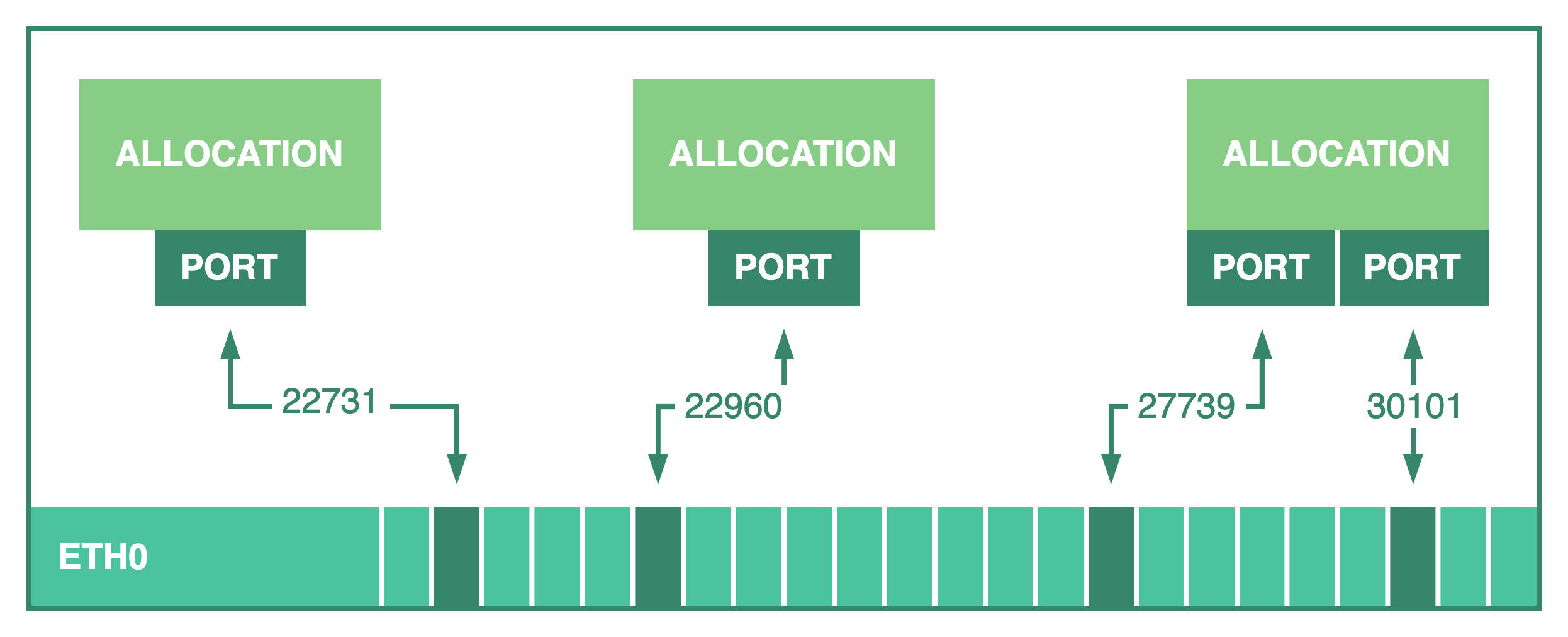
The selected port number can be accessed by tasks using the
NOMAD_PORT_<label> environment variable to bind and
expose the workload at the client's IP address and the given port.
The specific configuration process depends on what you are running, but it is
usually done using a configuration file rendered from a template or
passed directly via command line arguments:
It is also possible to request a specific port number, instead of a random one,
by setting a static value for the port. This should only be used by
specialized workloads, such as load balancers and system jobs, since it can
be hard to manage them manually to avoid scheduling collisions.
With the task listening at one of the client's ports, other processes can access it directly using the client's IP and port, but first they need to find these values. This process is called service discovery.
When using IP and port to connect allocations it is important to make sure your network topology and routing configuration allow the Nomad clients to communicate with each other.
Bridge networking
Linux clients support a network mode called bridge. A
bridge network acts like a virtual network switch allowing processes connected
to the bridge to reach each other while isolating them from others.
When an allocation uses bridge networking, the Nomad agent creates a bridge
called nomad (or the value set in bridge_network_name) using the
bridge CNI plugin if one doesn't exist yet. Before using this
mode you must first install the CNI plugins into your clients.
By default a single bridge is created in each Nomad client.
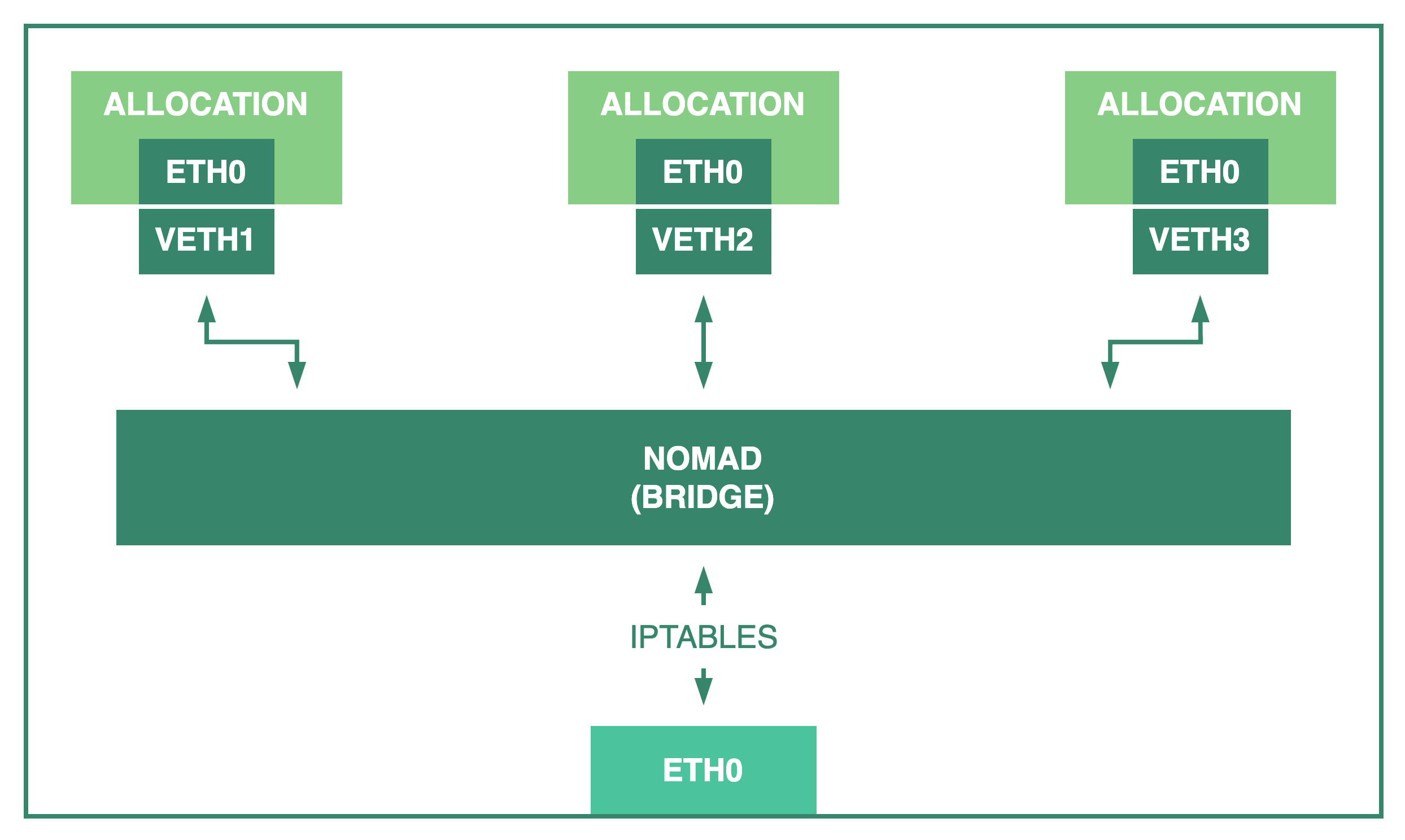
Allocations that use the bridge network mode run in an isolated network
namespace and are connected to the bridge. This allows Nomad to map random
ports from the host to specific port numbers inside the allocation that are
expected by the tasks.
For example, an HTTP server that listens on port 3000 by default can be
configured with the following network block:
To allow communication between allocations in different clients, Nomad creates
an iptables rule to forward requests from the host network interface to the
bridge. This results in three different network access scopes:
Tasks that bind to the loopback interface (
localhostor127.0.0.1) are accessible only from within the allocation.Tasks that bind to the bridge (or other general addresses, such as
0.0.0.0) withoutportforwarding are only accessible from within the same client.Tasks that bind to the bridge (or other general addresses, such as
0.0.0.0) withportforwarding are accessible from external sources.
Warning: To prevent any type of external access when using bridge
network mode make sure to bind your workloads to the loopback interface
only.
Bridge networking is at the core of service mesh and a requirement when using Consul Service Mesh.
Bridge networking with Docker
The Docker daemon manages its own network configuration and creates its own
bridge network, network namespaces, and iptable
rules. Tasks using the docker task driver connect to the
Docker bridge instead of using the one created by Nomad and, by default, each
container runs in its own Docker managed network namespace.
When using bridge network mode, Nomad creates a placeholder container using
the image defined in infra_image to initialize a Docker network namespace
that is shared by all tasks in the allocation to allow them to communicate with
each other.
The Docker task driver has its own task-level
network_mode configuration. Its default value depends
on the group-level network.mode configuration.
Warning: The task-level network_mode may conflict with the group-level
network.mode configuration and generate unexpected results. If you set the
group network.mode = "bridge" you should not set the Docker config
network_mode.
The diagram below illustrates what happens when a Docker task is configured incorrectly.
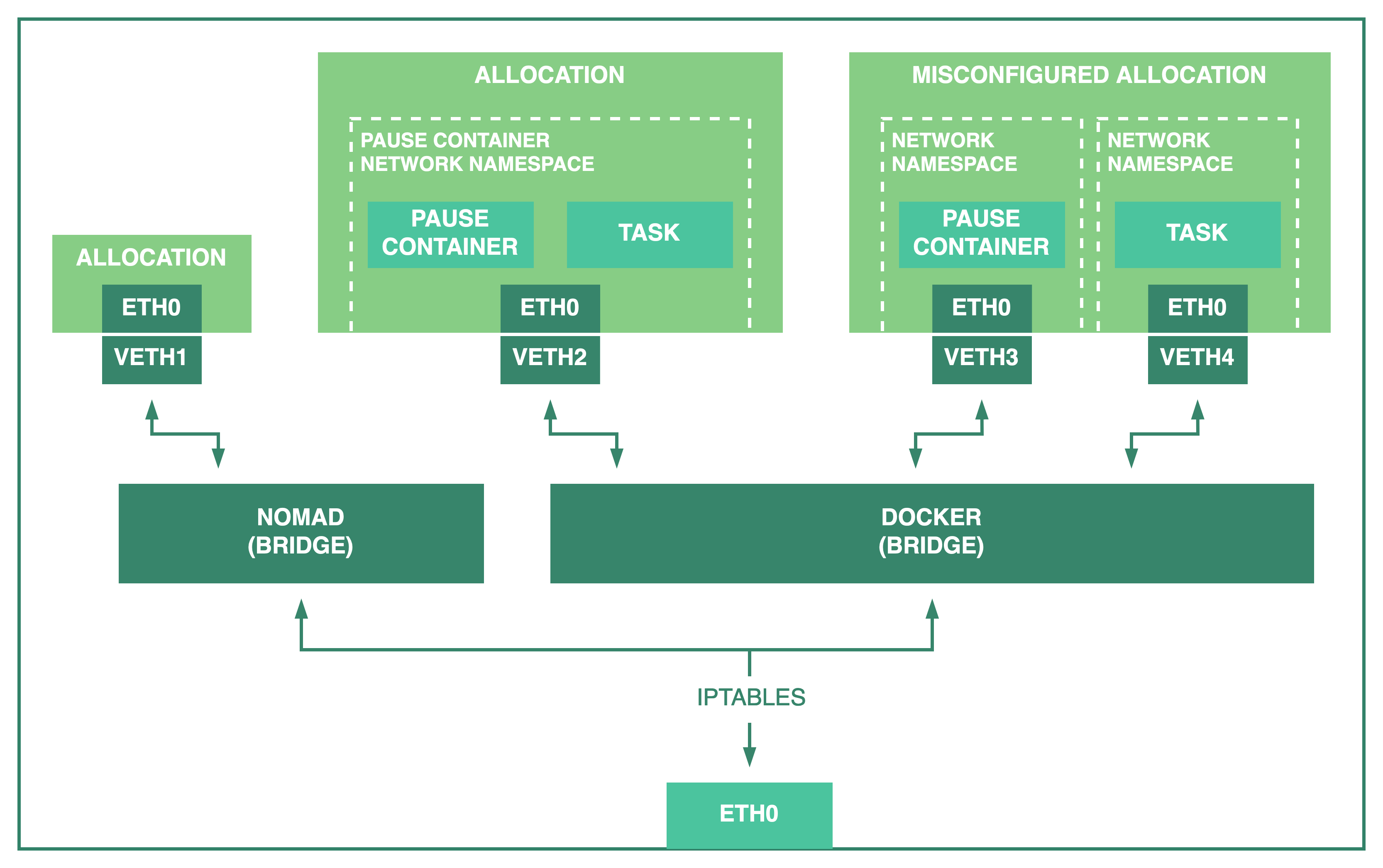
The tasks in the rightmost allocation are not able to communicate with each other using their loopback interface because they were placed in different network namespaces.
Since the group network.mode is bridge, Nomad creates the pause container
to establish a shared network namespace for all tasks, but setting the
task-level network_mode to bridge places the task in a different namespace.
This prevents, for example, a task from communicating with its sidecar proxy in
a service mesh deployment.
Refer to the network_mode documentation and the
Networking section for more information.
Note: Docker Desktop in non-Linux environments runs a local virtual machine, adding an extra layer of indirection. Refer to the FAQ for more details.
Comparing with other tools
Kubernetes and Docker Compose
Networking in Kubernetes and Docker Compose works differently than in Nomad. To
access a container you use a fully qualified domain name such as db in Docker
Compose or db.prod.svc.cluster.local in Kubernetes. This process relies on
additional infrastructure to resolve the hostname and distribute the requests
across multiple containers.
Docker Compose allows you to run and manage multiple containers using units called services.
To access a service from another container you can reference the service name
directly, for example using postgres://db:5432. In order to enable this
pattern, Docker Compose includes an internal DNS services and a
load balancer that is transparent to user. When running in Swarm mode, Docker
Compose also requires an overlay network to route requests across hosts.
Kubernetes provides the Service abstraction that can be used
to declare how a set of Pods are accessed.
To access the Service you use a FQDN such as
my-service.prod.svc.cluster.local. This name is resolved by the DNS
service which is an add-on that runs in all nodes. Along with this
service, each node also runs a kube-proxy instance to
distribute requests to all Pods matched by the Service.
You can use the same FQDN networking style with Nomad using Consul's DNS interface and configuring your clients with DNS forwarding, and deploying a load balancer.
Another key difference from Nomad is that in Kubernetes and Docker Compose each
container has its own IP address, requiring a virtual network to map physical
IP addresses to virtual ones. In case of Docker Compose in Swarm mode an
overlay is also required to enable traffic across multiple
hosts. This allows multiple containers running the same service to listen on
the same port number.
In Nomad, allocations use the IP address of the client they are running and are
assigned random port numbers and so Nomad service discovery with DNS uses
SRV records instead of A or AAA records.