Architecture
Nomad is a complex system that has many different pieces. To help both users and developers of Nomad build a mental model of how it works, this page documents the system architecture.
Advanced Topic! This page covers technical details of Nomad. You do not need to understand these details to effectively use Nomad. The details are documented here for those who wish to learn about them without having to go spelunking through the source code.
Glossary
Before describing the architecture, we provide a glossary of terms to help clarify what is being discussed:
Job - A Job is a specification provided by users that declares a workload for Nomad. A Job is a form of desired state; the user is expressing that the job should be running, but not where it should be run. The responsibility of Nomad is to make sure the actual state matches the user desired state. A Job is composed of one or more task groups.
Task Group - A Task Group is a set of tasks that must be run together. For example, a web server may require that a log shipping co-process is always running as well. A task group is the unit of scheduling, meaning the entire group must run on the same client node and cannot be split.
Driver – A Driver represents the basic means of executing your Tasks. Example Drivers include Docker, QEMU, Java, and static binaries.
Task - A Task is the smallest unit of work in Nomad. Tasks are executed by drivers, which allow Nomad to be flexible in the types of tasks it supports. Tasks specify their driver, configuration for the driver, constraints, and resources required.
Client - A Client of Nomad is a machine that tasks can be run on. All clients run the Nomad agent. The agent is responsible for registering with the servers, watching for any work to be assigned and executing tasks. The Nomad agent is a long lived process which interfaces with the servers.
Allocation - An Allocation is a mapping between a task group in a job and a client node. A single job may have hundreds or thousands of task groups, meaning an equivalent number of allocations must exist to map the work to client machines. Allocations are created by the Nomad servers as part of scheduling decisions made during an evaluation.
Evaluation - Evaluations are the mechanism by which Nomad makes scheduling decisions. When either the desired state (jobs) or actual state (clients) changes, Nomad creates a new evaluation to determine if any actions must be taken. An evaluation may result in changes to allocations if necessary.
Server - Nomad servers are the brains of the cluster. There is a cluster of servers per region and they manage all jobs and clients, run evaluations, and create task allocations. The servers replicate data between each other and perform leader election to ensure high availability. Servers federate across regions to make Nomad globally aware.
Regions and Datacenters - Nomad models infrastructure as regions and datacenters. Regions may contain multiple datacenters. Servers are assigned to a specific region, managing state and making scheduling decisions within that region. Multiple regions can be federated together. For example, you may have a
USregion with theus-east-1andus-west-1datacenters, connected to theEUregion with theeu-fr-1andeu-uk-1datacenters. Requests that are made between regions are forwarded to the appropriate servers. Data is not replicated between regions.Bin Packing - Bin Packing is the process of filling bins with items in a way that maximizes the utilization of bins. This extends to Nomad, where the clients are "bins" and the items are task groups. Nomad optimizes resources by efficiently bin packing tasks onto client machines.
High-Level Overview
Looking at only a single region, at a high level Nomad looks like this:
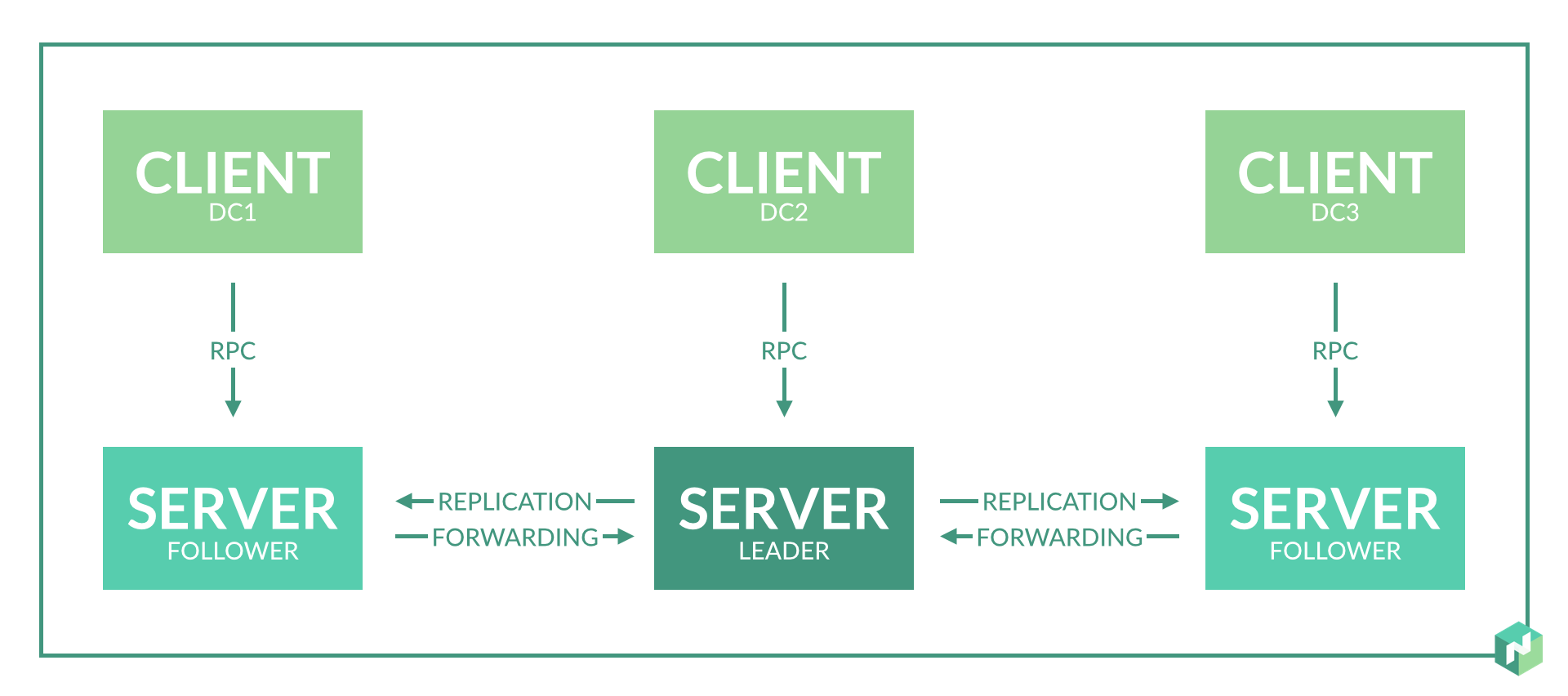
Within each region, we have both clients and servers. Servers are responsible for accepting jobs from users, managing clients, and computing task placements. Each region may have clients from multiple datacenters, allowing a small number of servers to handle very large clusters.
In some cases, for either availability or scalability, you may need to run multiple regions. Nomad supports federating multiple regions together into a single cluster. At a high level, this setup looks like this:
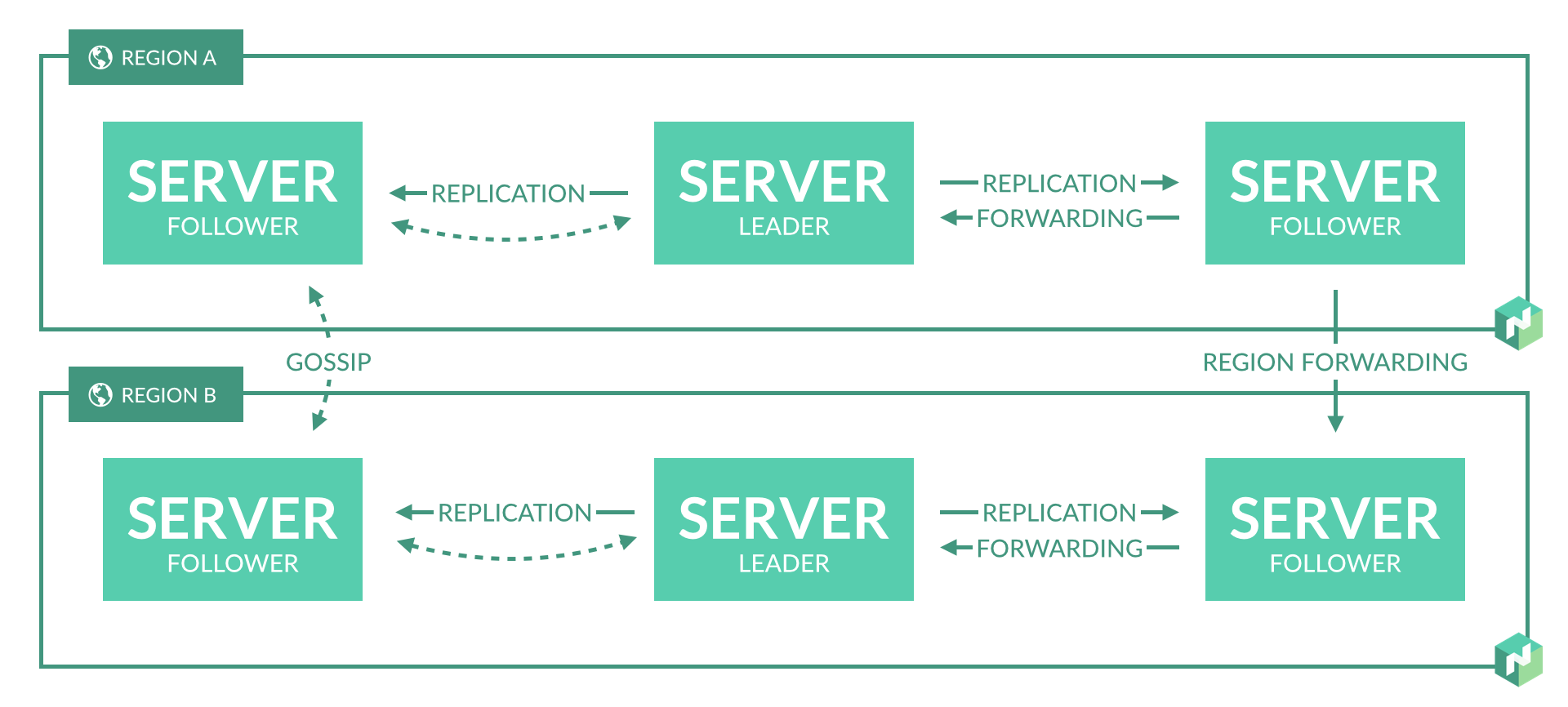
Regions are fully independent from each other, and do not share jobs, clients, or state. They are loosely-coupled using a gossip protocol, which allows users to submit jobs to any region or query the state of any region transparently. Requests are forwarded to the appropriate server to be processed and the results returned. Data is not replicated between regions.
The servers in each region are all part of a single consensus group. This means that they work together to elect a single leader which has extra duties. The leader is responsible for processing all queries and transactions. Nomad is optimistically concurrent, meaning all servers participate in making scheduling decisions in parallel. The leader provides the additional coordination necessary to do this safely and to ensure clients are not oversubscribed.
Each region is expected to have either three or five servers. This strikes a balance between availability in the case of failure and performance, as consensus gets progressively slower as more servers are added. However, there is no limit to the number of clients per region.
Clients are configured to communicate with their regional servers and communicate using remote procedure calls (RPC) to register themselves, send heartbeats for liveness, wait for new allocations, and update the status of allocations. A client registers with the servers to provide the resources available, attributes, and installed drivers. Servers use this information for scheduling decisions and create allocations to assign work to clients.
Users make use of the Nomad CLI or API to submit jobs to the servers. A job represents a desired state and provides the set of tasks that should be run. The servers are responsible for scheduling the tasks, which is done by finding an optimal placement for each task such that resource utilization is maximized while satisfying all constraints specified by the job. Resource utilization is maximized by bin packing, in which the scheduling tries to make use of all the resources of a machine without exhausting any dimension. Job constraints can be used to ensure an application is running in an appropriate environment. Constraints can be technical requirements based on hardware features such as architecture and availability of GPUs, or software features like operating system and kernel version, or they can be business constraints like ensuring PCI compliant workloads run on appropriate servers.
Getting in Depth
This has been a brief high-level overview of the architecture of Nomad. There are more details available for each of the sub-systems. The consensus protocol, gossip protocol, and scheduler design are all documented in more detail.
For other details, either consult the code, ask in IRC or reach out to the mailing list.