HTTP API
The main interface to Nomad is a RESTful HTTP API. The API can query the current state of the system as well as modify the state of the system. The Nomad CLI actually invokes Nomad's HTTP for many commands.
Version Prefix
All API routes are prefixed with /v1/.
Addressing and Ports
Nomad binds to a specific set of addresses and ports. The HTTP API is served via
the http address and port. This address:port must be accessible locally. If
you bind to 127.0.0.1:4646, the API is only available from that host. If you
bind to a private internal IP, the API will be available from within that
network. If you bind to a public IP, the API will be available from the public
Internet (not recommended).
The default port for the Nomad HTTP API is 4646. This can be overridden via
the Nomad configuration block. Here is an example curl request to query a Nomad
server with the default configuration:
The conventions used in the API documentation do not list a port and use the
standard URL localhost:4646. Be sure to replace this with your Nomad agent URL
when using the examples.
Data Model and Layout
There are five primary nouns in Nomad:
- jobs
- nodes
- allocations
- deployments
- evaluations
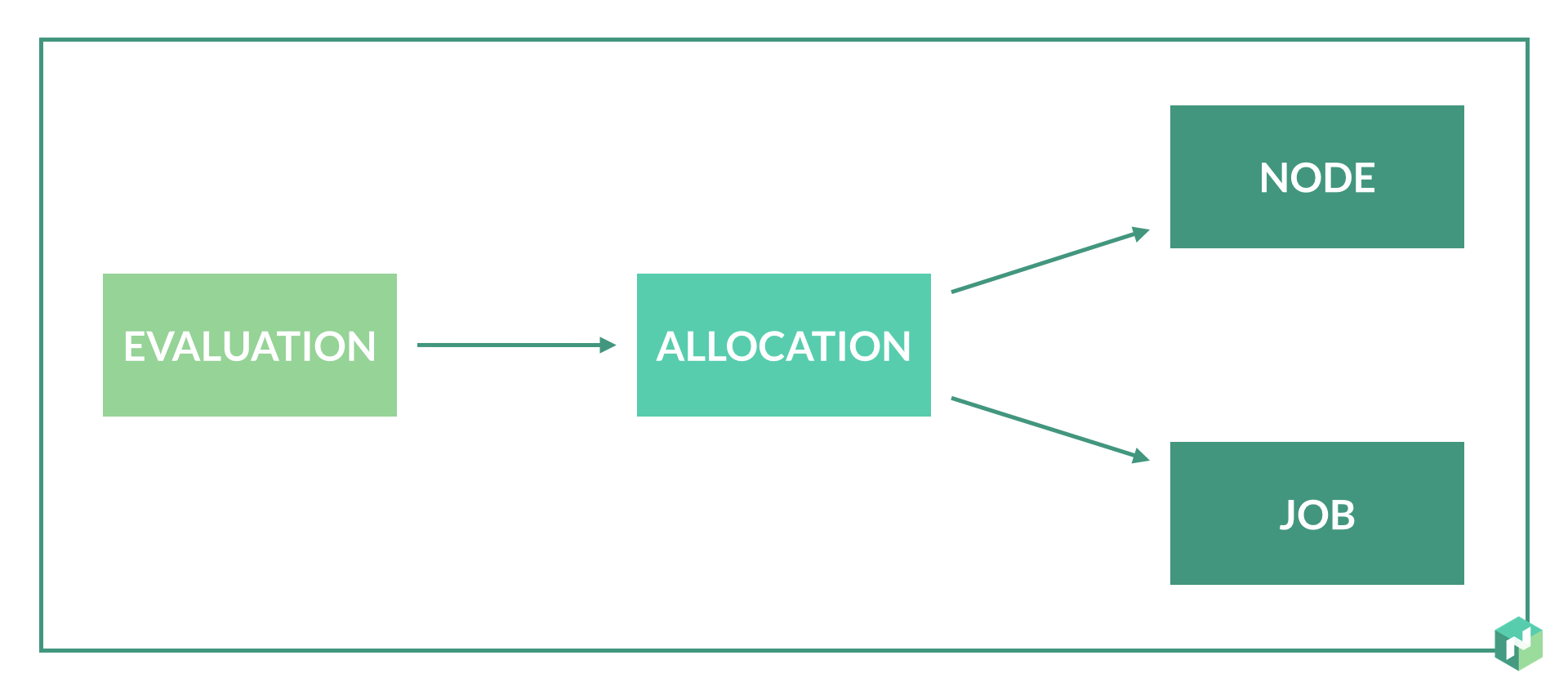
Jobs are submitted by users and represent a desired state. A job is a declarative description of tasks to run which are bounded by constraints and require resources. Jobs can also have affinities which are used to express placement preferences. Nodes are the servers in the clusters that tasks can be scheduled on. The mapping of tasks in a job to nodes is done using allocations. An allocation is used to declare that a set of tasks in a job should be run on a particular node. Scheduling is the process of determining the appropriate allocations and is done as part of an evaluation. Deployments are objects to track a rolling update of allocations between two versions of a job.
The API is modeled closely on the underlying data model. Use the links to the left for documentation about specific endpoints. There are also "Agent" APIs which interact with a specific agent and not the broader cluster used for administration.
ACLs
Several endpoints in Nomad use or require ACL tokens to operate. The token are used to authenticate the request and determine if the request is allowed based on the associated authorizations. Tokens are specified per-request by using the X-Nomad-Token request header or with the Bearer scheme in the authorization header set to the SecretID of an ACL Token.
For more details about ACLs, please see the ACL Guide.
Authentication
When ACLs are enabled, a Nomad token should be provided to API requests using the X-Nomad-Token header or with the Bearer scheme in the authorization header. When using authentication, clients should communicate via TLS.
Here is an example using curl with X-Nomad-Token:
Below is an example using curl with a RFC6750 Bearer token:
Namespaces
Nomad has support for namespaces, which allow jobs and their associated objects to be segmented from each other and other users of the cluster. When using non-default namespace, the API request must pass the target namespace as an API query parameter. Prior to Nomad 1.0 namespaces were Enterprise-only.
Here is an example using curl:
Filtering
Filter expressions refine data queries for some API listing endpoints, as notated in the individual API endpoints documentation.
To create a filter expression, you will write one or more expressions. Each expression has matching operators composed of selectors and values.
Filtering is executed on the Nomad server, before data is returned, reducing
the network load. To pass a filter expression to Nomad, use the filter query
parameter with the URL encoded expression when sending requests to HTTP API
endpoints that support it.
Some endpoints may have other query parameters that are used for filtering, but
they can't be used with the filter query parameter. Doing so will result in a
400 status error response. These query parameters are usually backed by a
database index, so they may be prefereable over an equivalent simple filter
expression due to better resource usage and performance.
Creating Expressions
A single expression is a matching operator with a selector and value and they are written in plain text format. Boolean logic and parenthesization are supported. In general, whitespace is ignored, except within literal strings.
Matching Operators
All matching operators use a selector or value to choose what data should be matched. Each endpoint that supports filtering accepts a potentially different list of selectors and is detailed in the API documentation for those endpoints.
Selectors
Selectors are used by matching operators to create an expression. They are
defined by a . separated list of names. Each name must start with an ASCII
letter and can contain ASCII letters, numbers, and underscores. When part of
the selector references a map value it may be expressed using the form
["<map key name>"] instead of .<map key name>. This allows the possibility
of using map keys that are not valid selectors in and of themselves.
Values
Values are used by matching operators to create an expression. Values can be any valid selector, a number, or a string. It is best practice to quote values. Numbers can be base 10 integers or floating point numbers.
When quoting strings, they may either be enclosed in double quotes or
backticks. When enclosed in backticks they are treated as raw strings and
escape sequences such as \n will not be expanded.
Connecting Expressions
There are several methods for connecting expressions, including:
- logical
or - logical
and - logical
not - grouping with parenthesis
- matching expressions
Standard operator precedence can be expected for the various forms. For example, the following two expressions would be equivalent.
Filter Utilization
Generally, only the main object is filtered. When filtering for an item within an array that is not at the top level, the entire array that contains the item will be returned. This is usually the outermost object of a response, but in some cases the filtering is performed on a object embedded within the results.
Performance
Filters are executed on the servers and therefore will consume some amount of CPU time on the server. For non-stale queries this means that the filter is executed on the leader.
Filtering Examples
Jobs API
Command (Unfiltered)
Response (Unfiltered)
Command (Filtered)
Response (Filtered)
Deployments API
Command (Unfiltered)
Response (Unfiltered)
Command (Filtered)
Response (Filtered)
Pagination
Some list endpoints support partial results to limit the amount of data
retrieved. The returned list is split into pages and the page size can be set
using the per_page query parameter with a positive integer value.
If more data is available past the page requested, the response will contain an
HTTP header named X-Nomad-Nexttoken with the value of the next item to be
retrieved. This value can then be set as a query parameter called next_token
in a follow-up request to retrieve the next page.
When the last page is reached, the X-Nomad-Nexttoken HTTP header will not
be present in the response, indicating that there is nothing more to return.
Ordering
List results are usually returned in ascending order by their internal key,
such as their ID. Some endpoints may return data sorted by their
CreateIndex value, which roughly corelates to their creation order. The
result order may be reversed using the reverse=true query parameter when
supported by the endpoint.
Blocking Queries
Many endpoints in Nomad support a feature known as "blocking queries". A blocking query is used to wait for a potential change using long polling. Not all endpoints support blocking, but each endpoint uniquely documents its support for blocking queries in the documentation.
Endpoints that support blocking queries return an HTTP header named
X-Nomad-Index. This is a unique identifier representing the current state of
the requested resource. On a new Nomad cluster the value of this index starts at 1.
On subsequent requests for this resource, the client can set the index query
string parameter to the value of X-Nomad-Index, indicating that the client
wishes to wait for any changes subsequent to that index.
When this is provided, the HTTP request will "hang" until a change in the system occurs, or the maximum timeout is reached. A critical note is that the return of a blocking request is no guarantee of a change. It is possible that the timeout was reached or that there was an idempotent write that does not affect the result of the query.
In addition to index, endpoints that support blocking will also honor a wait
parameter specifying a maximum duration for the blocking request. This is
limited to 10 minutes. If not set, the wait time defaults to 5 minutes. This
value can be specified in the form of "10s" or "5m" (i.e., 10 seconds or 5
minutes, respectively). A small random amount of additional wait time is added
to the supplied maximum wait time to spread out the wake up time of any
concurrent requests. This adds up to wait / 16 additional time to the maximum
duration.
Consistency Modes
Most of the read query endpoints support multiple levels of consistency. Since no policy will suit all clients' needs, these consistency modes allow the user to have the ultimate say in how to balance the trade-offs inherent in a distributed system.
The two read modes are:
default- If not specified, the default is strongly consistent in almost all cases. However, there is a small window in which a new leader may be elected during which the old leader may service stale values. The trade-off is fast reads but potentially stale values. The condition resulting in stale reads is hard to trigger, and most clients should not need to worry about this case. Also, note that this race condition only applies to reads, not writes.stale- This mode allows any server to service the read regardless of whether it is the leader. This means reads can be arbitrarily stale; however, results are generally consistent to within 50 milliseconds of the leader. The trade-off is very fast and scalable reads with a higher likelihood of stale values. Since this mode allows reads without a leader, a cluster that is unavailable will still be able to respond to queries.
To switch these modes, use the stale query parameter on requests.
To support bounding the acceptable staleness of data, responses provide the
X-Nomad-LastContact header containing the time in milliseconds that a server
was last contacted by the leader node. The X-Nomad-KnownLeader header also
indicates if there is a known leader. These can be used by clients to gauge the
staleness of a result and take appropriate action.
Cross-Region Requests
By default, any request to the HTTP API will default to the region on which the
machine is servicing the request. If the agent runs in "region1", the request
will query the region "region1". A target region can be explicitly request using
the ?region query parameter. The request will be transparently forwarded and
serviced by a server in the requested region.
Compressed Responses
The HTTP API will gzip the response if the HTTP request denotes that the client accepts gzip compression. This is achieved by passing the accept encoding:
Formatted JSON Output
By default, the output of all HTTP API requests is minimized JSON. If the client
passes pretty on the query string, formatted JSON will be returned.
In general, clients should prefer a client-side parser like jq instead of
server-formatted data. Asking the server to format the data takes away
processing cycles from more important tasks.
HTTP Methods
Nomad's API aims to be RESTful, although there are some exceptions. The API responds to the standard HTTP verbs GET, PUT, and DELETE. Each API method will clearly document the verb(s) it responds to and the generated response. The same path with different verbs may trigger different behavior. For example:
Even though these share a path, the PUT operation creates a new job whereas
the GET operation reads all jobs.
HTTP Response Codes
Individual API's will contain further documentation in the case that more specific response codes are returned but all clients should handle the following:
- 200 and 204 as success codes.
- 400 indicates a validation failure and if a parameter is modified in the request, it could potentially succeed.
- 403 marks that the client isn't authenticated for the request.
- 404 indicates an unknown resource.
- 5xx means that the client should not expect the request to succeed if retried.